



.jpg)
.jpg)
.jpg)
.jpeg)
.png)
.png)
.png)
.png)
.png)
.jpeg)
.jpeg)
.jpeg)
%2520(1).png)









.avif)








.png)

.png)
.png)





.png)
![Agent Server [1/3]: Where Enterprise AI Agents Live, Work, and Scale](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcea_690e4d0f068d3ec27aea7ae0_123%2520(1).png)
![Agent Server [2/3]: Where Should Your Agent Server Run?](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcf0_690e646b6e0366d090fbc37f_wdxczxgr-1.png)
![Agent Server [3/3]: Agent Access Control Explained: RBAC, Caller Limits, and Safer A2A](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b56c87a1735a82bac8d_69132a45740300abc320bc7f_Cover_%2520RBAC%2520for%2520Agents%252C%2520Done%2520Right2%2520(1).png)
.png)
.jpeg)
.png)

%25201%2520(1).jpeg)

%25201%2520(1).jpeg)
.jpeg)
.jpeg)
July 21, 2026
A Living Memory of Your Enterprise Context — The Genesis Context Graph
.jpg)

.jpg)
TL;DR: Genesis Computing, founded by ex-Goldman Sachs and ex-Snowflake executive Matthew Glickman, builds data engineering automation software that deploys inside enterprise data environments; Snowflake, Databricks, AWS, and others. The platform takes over the repetitive, time-consuming parts of data pipeline work so engineers can focus on higher-value projects. The real measure of success: time saved, not headcount added.
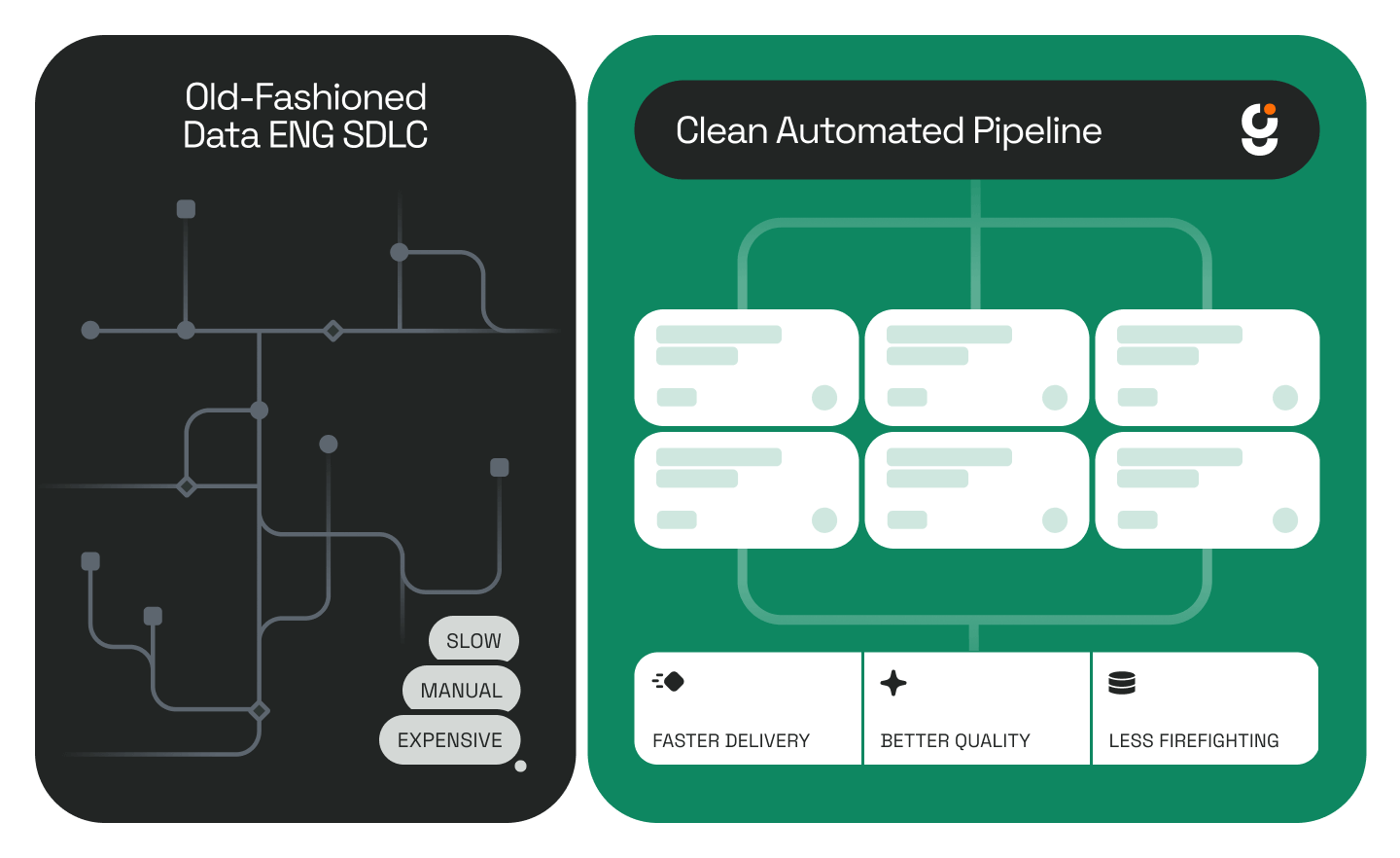
Data engineers are in a strange spot. They are indispensable, constantly buried in work, and yet largely invisible until something breaks. There is a well-known joke in the field: the only time anyone learns a data engineer's name is when a pipeline goes down.
That invisibility comes at a cost. Most data engineering teams spend the majority of their time maintaining existing pipelines, chasing down broken jobs, and translating business requirements into working code, leaving very little bandwidth for anything else. According to IDC research, data engineering teams at mid-market companies spend 60 to 70 percent of their time on pipeline maintenance rather than new development.
More volume, more complexity, and more pressure from leadership to "do something with AI," without more headcount. That is where most teams are right now.
Genesis Computing was built to change that math.
Matthew Glickman spent years at Goldman Sachs running quantitative data teams, then led product at Snowflake. During that time, he watched the same pattern repeat at enterprise after enterprise: teams would build impressive demos using large language models, then hit a wall when it came to production reliability.
"Everyone was trying to build a framework around these powerful models to unlock their data teams," Glickman explained on The Data Exchange podcast. "My co-founder Justin Langseth and I realized, given what we knew about the space, why not build this once in a way that all these enterprises could use?"
The specific insight was about which use case to target. Most early AI tooling in the enterprise focused on the most visible, high-stakes interactions: the CFO asking open-ended questions, the analyst pulling live reports. Glickman saw a more reliable entry point: the data engineer, who has more work than time, is already comfortable with automation, and just needs something that actually works in production.
The result is a platform that deploys data pipeline automation inside a customer's existing environment and handles the mechanics of pipeline construction, source-to-target mapping, and ETL execution, without requiring engineers to write every line from scratch.
Genesis installs directly inside a customer's data environment: Snowflake, Databricks, AWS, Azure, or Docker. It connects to existing data sources, catalogs, and external systems. From there, an engineer describes what they are trying to build, and Genesis handles the execution.
The workflow looks like this:
That last point is central to how Genesis handles the reliability problem that trips up most automation projects. The system is designed to know when to stop and ask, rather than rolling the dice and leaving a wrong answer for a human to catch later.
For teams dealing with legacy system migrations, COBOL, SAP, Oracle, Informatica, Genesis reads the source code and documentation directly, producing human-readable documentation of what the system actually does before writing a single line of new code. In one case, the system surfaced a customer classification rule in a legacy SAP codebase that a traditional consulting team had missed entirely over six months of work. (The rule was written using German field abbreviations, which the model recognized without being told.)
Enterprise data teams often consider building their own tooling internally. Glickman's take is direct: build what is core to your business, and buy everything else.
"If you can build a product and make money from it, build it. But if you're building it internally for cost, someone building it for revenue will always build it better," he said.
The maintenance reality tends to resolve the debate. Internal tooling needs to be supported indefinitely, updated as models improve, and rebuilt when requirements change. For most teams, that is not where their engineering effort should go.
For more on how Genesis handles deployment and environment setup, see Connecting Data Sources in Genesis.
The most consistent response Genesis gets from data engineers seeing the platform for the first time is skepticism, followed by interest. The skepticism is reasonable: the pitch sounds too clean. Glickman's response is to demonstrate it in the actual environment rather than argue the point.
What engineers get in practice:
That last point on institutional knowledge is worth underscoring. When a senior engineer leaves, their understanding of edge cases, business rules, and undocumented system quirks typically walks out with them. Genesis absorbs that knowledge over time as it works inside the environment, turning tacit expertise into documented, searchable assets the whole team can use.
To see this in action, the Genesis Bronze, Silver, Gold pipeline walkthrough shows the full progression from a dashboard sketch to a production pipeline.
Glickman does not sidestep the workforce implication. The jobs most at risk are entry-level data engineering roles, the same positions that have traditionally been the on-ramp into the profession.
"The pipeline is going to be missing," he acknowledged. "There's a social contract that if you study hard and get internships, there will be jobs. The worst part is that schools aren't teaching AI as a core skill."
His argument is that the right response is not to slow down adoption, but to accelerate AI literacy in education. The data engineer does not disappear, they manage a larger scope. But the path from junior to senior changes, and that transition needs to be accounted for in how students are trained.
For a broader look at how the data engineering role is evolving, see The Evolution of Data Work: Introducing Agentic Data Engineering and The Future of Data Engineering: From Months to Hours.
Does Genesis replace data engineers? No. Genesis handles the repetitive, mechanics-heavy work so engineers can focus on higher-value projects. It functions more like a capable junior team member than a replacement.
Which data platforms does Genesis support? Genesis deploys natively on Snowflake, Databricks, AWS, Azure, and Docker. Documentation is available at docs.genesiscomputing.com.
How does Genesis handle reliability? What happens when it's not sure? The system is built to escalate to a human when it cannot produce a confident result, rather than generating a wrong answer and moving on. Engineers define what "correct" looks like; Genesis checks its work against that standard.
Can Genesis handle legacy systems like SAP or COBOL? Yes. Genesis reads legacy source code and documentation to understand what the system does, then produces new code and documentation from that understanding, rather than translating line by line.


.jpg)
.jpg)