



July 21, 2026
A Living Memory of Your Enterprise Context — The Genesis Context Graph
.jpg)


TL;DR: Giving an agent access to every tool at once is like opening every valve in a pipeline at the same time -- pressure drops, accuracy slips, and debugging becomes a nightmare. Progressive tool use keeps that flow regulated: activate only the tools needed for the current stage, link outputs to the next input, close tools when the work is done, and log any gaps for later review. When tools, context, and blueprints align, agents stop improvising and start operating like disciplined data engineers.
In Part 1 -- Blueprints, I explained how agents follow structured workflows instead of improvising. In Part 2 -- Context Management, I talked about how they keep their heads clear across hundreds of steps. This last part is about the execution layer: how agents decide which tools to bring into scope at each stage of a data workflow, and how to keep reasoning stable as the environment grows.
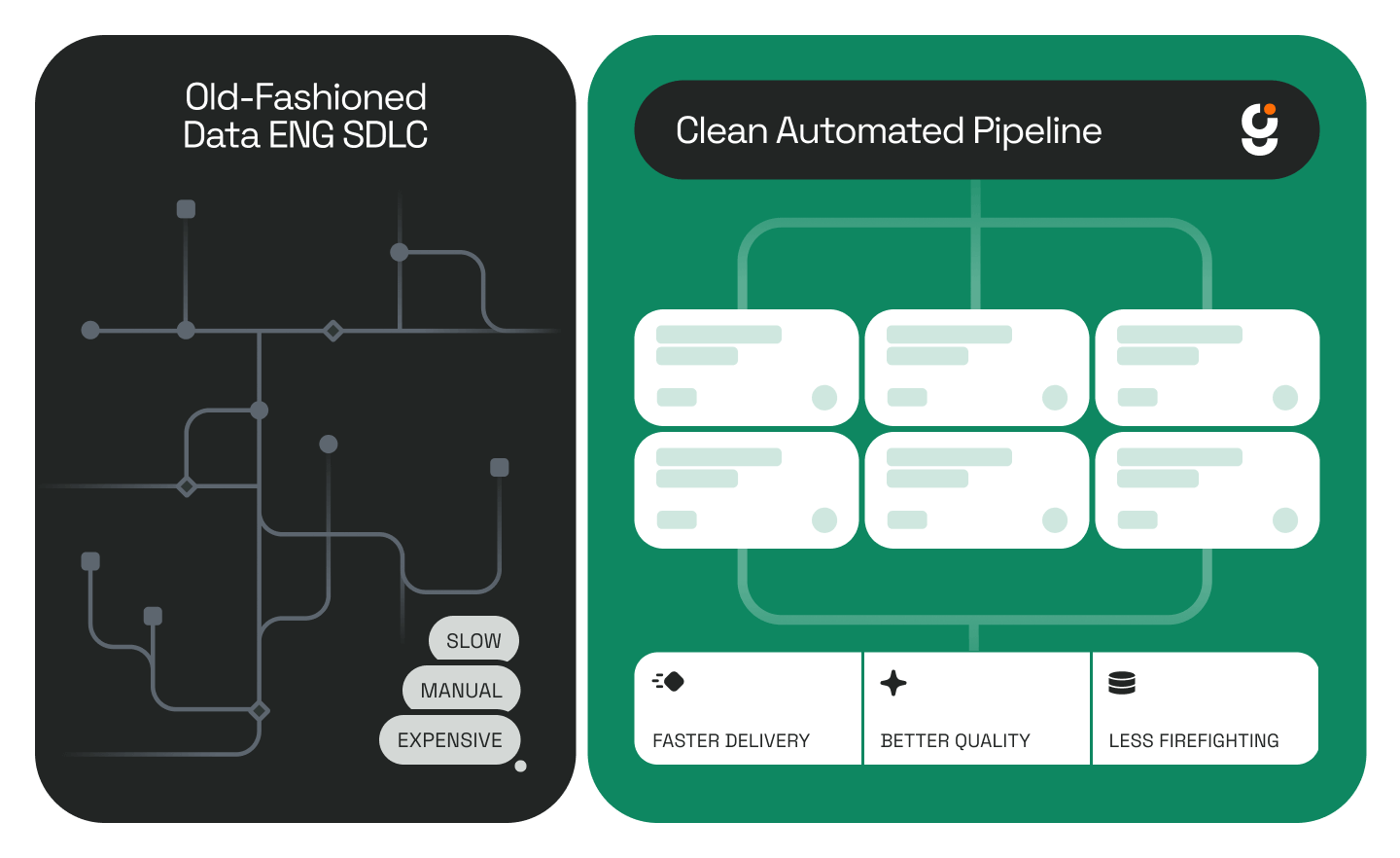
Anyone who's managed complex data pipelines knows what happens when everything connects to everything else. You end up with overlapping jobs, half-deprecated connectors, and a DAG that only works if nobody touches it. Large tool inventories cause the same chaos inside an agent's head. Every SQL client, catalog API, schema parser, and validation script expands the model's internal vocabulary. Even when half of them aren't needed, the model still carries the mental weight of choosing among them. The result is the same kind of backpressure you see when too many upstream jobs push into the same sink: performance drops, accuracy slips, and debugging turns into archaeology.
Tool orchestration in agent systems feels a lot like data plumbing. Each tool is a valve or a section of pipe that handles a specific part of the flow. If you open every valve at once, pressure drops and data backs up. Progressive tool use is about keeping that flow regulated.
.png)
The agent activates only the tools needed for the current stage of the blueprint, closes them when finished, and moves downstream with a clean workspace. It's controlled throughput instead of all-or-nothing concurrency. This maps closely to what researchers studying utility-guided agent orchestration have identified as the core tension in multi-step agent execution: additional tool calls improve coverage but compound latency and context growth at every step.
When one stage produces an output that becomes the input for the next, the agent links those tools directly. A metadata extraction might feed a schema inference step, which then passes its output to a validation layer. That linkage happens dynamically, so the tools stay in scope only as long as they're relevant. If the agent encounters a missing capability– say, a lineage tracer it can't find– it flags the gap instead of stalling. We log those requests, review them later, and decide whether the new connector belongs in the standard environment. That way, the system grows based on real use, not theoretical coverage.
Every active tool also adds cost: state to maintain, query context to remember, and latency that compounds across long chains of calls. When the agent finishes a section of work, it drops that state and releases the connectors. That automatic cleanup keeps long-running blueprints deterministic. We've seen what happens when cleanup is skipped – metrics drift, transformations desynchronize, and the whole run becomes non-reproducible. So cleanup isn't optional; it's part of the discipline, just like versioning or lineage tracking.
We're still learning what "too many tools" means. It depends on the model family, the schema size, and how verbose the tools are. So far it seems safer to start minimal, expose only what's required, and let the system request expansions as it proves it needs them. That pattern mirrors good data engineering: maintain flow control, reduce width, and prevent context pollution at every stage.
As Anthropic's own engineering team puts it when writing about effective context engineering for agents, the goal is "finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome." The same logic applies to tools: fewer, better-scoped instruments produce more stable and predictable agent behavior than a wide-open inventory.
When tools, context, and blueprints align, the agent starts behaving like a disciplined data engineer. It knows which table it's touching, which lineage it belongs to, and which downstream step depends on its output. That's when automation stops feeling like orchestration and starts looking like real operational intelligence – a system that understands, executes, and maintains the integrity of data flow at scale.
.png)
To see this pattern in action, see how Genesis agents execute a full dbt project end to end using exactly this kind of staged, controlled tool activation.
What is progressive tool use in agent systems? Progressive tool use means an agent activates only the tools required for its current stage of work, closes them when that stage is complete, and moves to the next step with a clean slate. Instead of loading an entire tool inventory upfront, the agent expands its toolset incrementally based on what each phase of the workflow actually needs.
Why does giving an agent too many tools cause problems? Every tool an agent has access to adds to its internal decision space -- even tools that aren't being used. That overhead creates the same kind of backpressure you see in an overloaded data pipeline: performance drops, accuracy slips, and tracing a problem back to its source becomes much harder. Keeping the active toolset small and stage-specific avoids that pressure. Weaviate's breakdown of context engineering for tools frames it well: it's not enough to hand an agent a list of APIs, the real work is making sure it knows which one to use, when, and how to interpret the result.
How does this relate to Genesis Blueprints? Blueprints define the sequence of stages an agent executes. Progressive tool use is the discipline that governs what tooling is active at each stage. Together, they ensure that the agent has exactly what it needs for the current phase of work and nothing extra, keeping long-running missions predictable and auditable. You can read more about how Blueprints work in Part 1 of this series.
Is there a recommended starting point for tool scope? Start minimal. Expose only the tools required for the first stage and let the system surface what it needs from there. As LlamaIndex notes in their guide to context engineering techniques, breaking complex tasks into focused steps with their own optimized context windows prevents overload and makes agent behavior easier to reason about. That conservative starting point produces more stable, easier-to-debug agent behavior than trying to anticipate every possible tool requirement upfront.
This is Part 3 of a three-part series. Look back on: Part 1 — Blueprints and Part 2 -- Context Management



.jpg)
.jpg)
.jpg)

.jpeg)
.png)
.png)
.png)
.png)
.png)
.jpeg)
.jpeg)
.jpeg)
.jpg)
%2520(1).png)
.jpg)


.jpeg)
%25201%2520(1).jpeg)

%25201%2520(1).jpeg)
.jpg)

.png)
.jpeg)
.png)
.png)
.png)
.avif)












![Agent Server [1/3]: Where Enterprise AI Agents Live, Work, and Scale](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcea_690e4d0f068d3ec27aea7ae0_123%2520(1).png)
![Agent Server [2/3]: Where Should Your Agent Server Run?](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcf0_690e646b6e0366d090fbc37f_wdxczxgr-1.png)
![Agent Server [3/3]: Agent Access Control Explained: RBAC, Caller Limits, and Safer A2A](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b56c87a1735a82bac8d_69132a45740300abc320bc7f_Cover_%2520RBAC%2520for%2520Agents%252C%2520Done%2520Right2%2520(1).png)


.png)
.png)



.jpeg)