



.jpg)
.jpg)
.jpg)
.jpeg)
.png)
.png)
.png)
.png)
.png)
.jpeg)
.jpeg)
.jpeg)
%2520(1).png)









.avif)








.png)

.png)
.png)





.png)
![Agent Server [1/3]: Where Enterprise AI Agents Live, Work, and Scale](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcea_690e4d0f068d3ec27aea7ae0_123%2520(1).png)
![Agent Server [2/3]: Where Should Your Agent Server Run?](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcf0_690e646b6e0366d090fbc37f_wdxczxgr-1.png)
![Agent Server [3/3]: Agent Access Control Explained: RBAC, Caller Limits, and Safer A2A](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b56c87a1735a82bac8d_69132a45740300abc320bc7f_Cover_%2520RBAC%2520for%2520Agents%252C%2520Done%2520Right2%2520(1).png)
.png)
.jpeg)
.png)

%25201%2520(1).jpeg)

%25201%2520(1).jpeg)
.jpeg)
.jpeg)
July 21, 2026
A Living Memory of Your Enterprise Context — The Genesis Context Graph
.jpg)

TL;DR: When a data pipeline breaks in a complex enterprise stack, the investigation alone can eat six-plus hours of senior engineering time. Genesis Twin automatically maps your entire data environment in real time so engineers and autonomous agents can diagnose and fix breaks fast, without the tribal knowledge archaeology.
The VP of Sales is escalating. Zero new leads hit territories over the weekend. Your engineers start pulling threads:
Three senior engineers. Six hours. Fifteen Slack threads. One very frustrated CRO.
This plays out constantly across data teams. The dataset changes. The outcome doesn't. When teams lack visibility into how data flows, small issues become major delays — an unexpected error triggers hours of backtracking through SQL logic, pipelines, and disconnected tools. Alation
The cost is real. Over 90% of midsize and large enterprises report that a single hour of downtime costs more than $300,000, with 41% putting it above $1 million per hour. The Network Installers
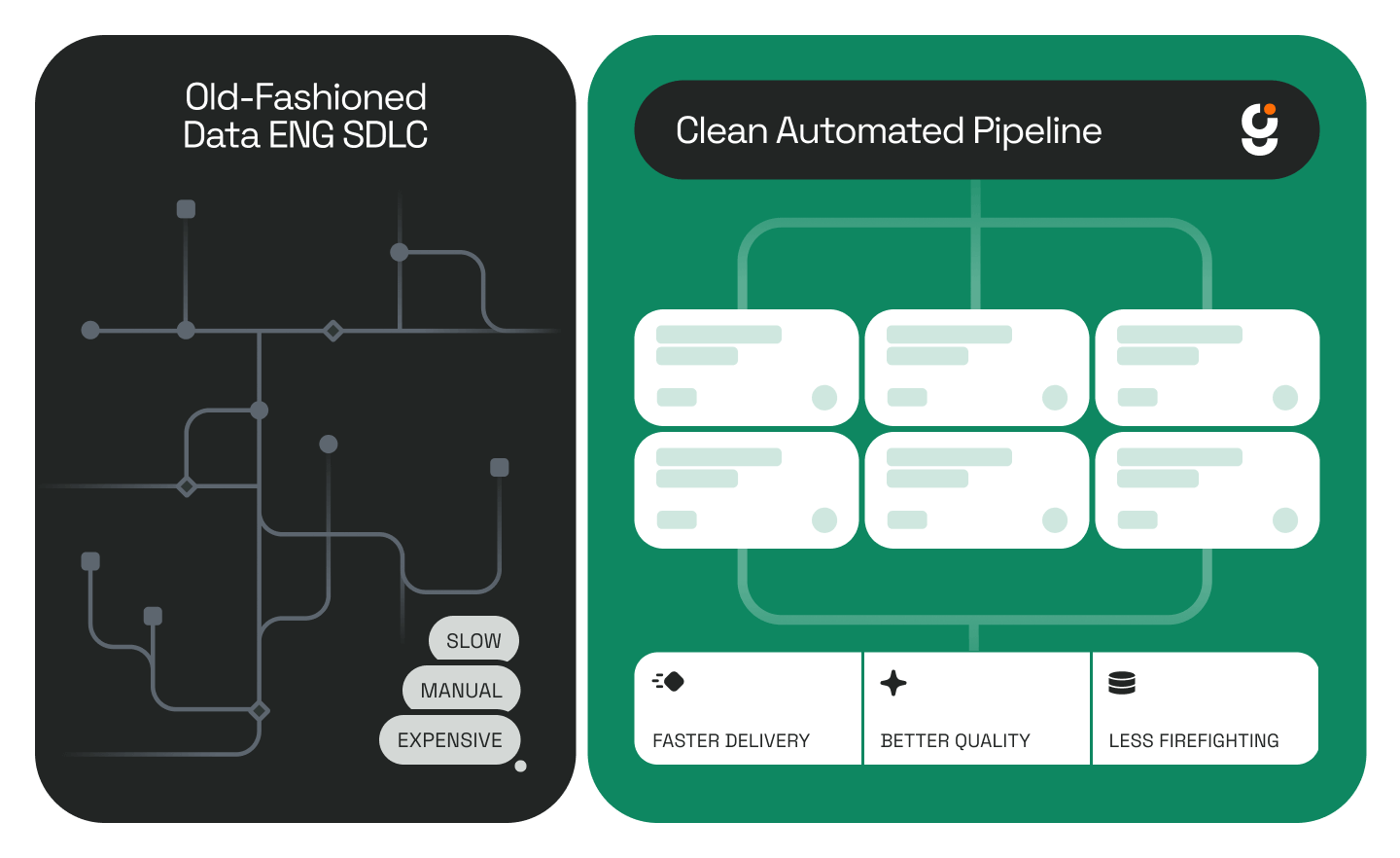
Enterprise data environments aren't built from a single blueprint. They accumulate over years: one team adds a CRM integration, another builds a custom sync, a third patches a connector and documents it somewhere nobody can find.
The result is tribal knowledge: context that lives in specific engineers' heads rather than in any system. When those engineers are unavailable, or when a pipeline with eight upstream dependencies breaks on a Saturday night, the investigation starts from scratch.
Enterprise environments often include dozens of systems built by different teams, at different times, for different purposes. Few were designed with the thought of how someone in 2025 would need to trace a business decision back to its source. TechTarget
Documentation alone can't fix this. It goes stale the moment a pipeline changes. What teams actually need is a live, continuously updated map of how data moves through their environment.
Twin automatically scans your entire data landscape and builds a real-time dependency graph across every system, table, integration, and connection. Unlike static documentation, a digital twin is updated continuously in near real time.
Twin eliminates the manual archaeology. Instead of reconstructing how everything connects from memory and old Slack threads, engineers have a live map they can actually trust.
Twin is the context layer that makes autonomous data engineering possible. With a complete picture of the environment, Genesis Data Engineering Agents can automate migrations, refactor pipelines, and fix breaks without turning your senior engineers into data detectives.
Undocumented infrastructure is a compounding liability. Every new integration added without visibility makes the next incident harder to resolve and the next migration riskier to execute.
IT and engineering teams pulled into outage investigations shift focus away from planned initiatives to problem-solving and recovery — and in regulated industries, downtime often means noncompliance. EnterpriseDB
The real issue isn't that engineers work slowly. It's that without a map of the environment, even the fastest engineers are starting from zero every time something breaks. Twin changes that.
What is a data infrastructure digital twin? A digital twin of your data infrastructure is a live, continuously updated model that maps how data flows across every system, table, and integration in your environment. Unlike documentation, it stays current automatically.
How is Twin different from a data catalog? Data catalogs typically focus on metadata and discoverability. Twin is specifically built to map dependencies and integration flows so engineers and agents can understand what connects to what and trace the impact of any change or break.
What systems does Twin connect to? Twin works across common enterprise stacks including Salesforce, Snowflake, and third-party integration layers. See the full list on the Genesis Computing website.
How does Twin support Genesis agents? Genesis Data Engineering Agents use Twin's context graph to execute complex work autonomously — pipeline migrations, refactors, break fixes — without needing a human to manually reconstruct the environment first. Read more about how Genesis agents work on the Genesis blog.
Is this only useful when something breaks? No. Twin is valuable proactively for impact analysis before making changes, planning migrations, and onboarding new engineers who need to understand how the environment is structured.

.jpg)
.jpg)
.jpg)