.png)




July 21, 2026
A Living Memory of Your Enterprise Context — The Genesis Context Graph
.jpg)

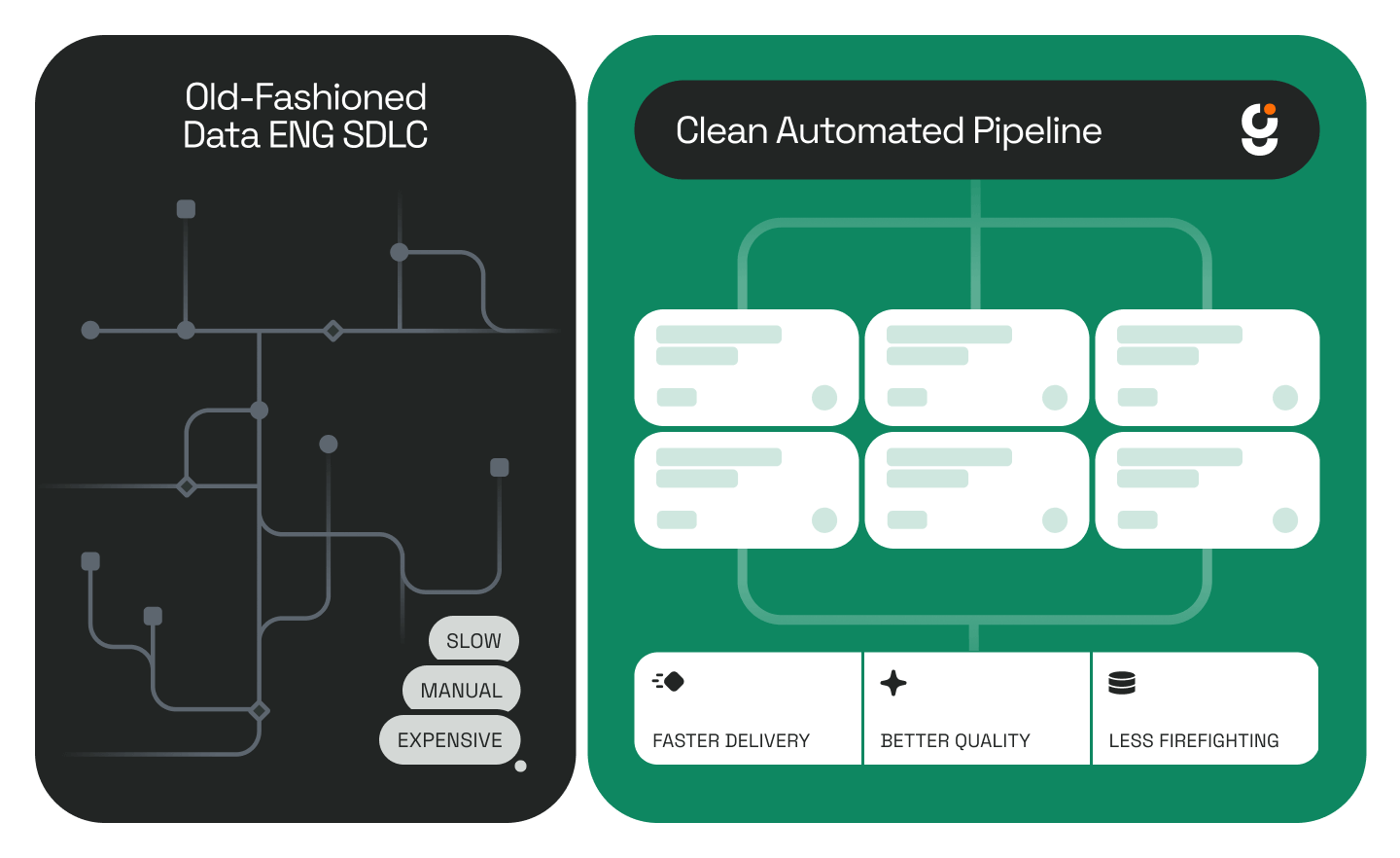
TL;DR: A growing data pipeline backlog isn't just a scheduling problem, it's a compounding business risk. Every delayed ticket represents a missed opportunity, a stalled decision, or a blind spot you don't know you have. The fix isn't more headcount; it's changing the way your team works. Automating the data lifecycle with purpose-built agents frees engineers to focus on strategy, and turns the backlog from a liability into a competitive advantage.
"Delay" is a common refrain we hear when talking to our prospects. Specifically, the delay caused by piling new data pipeline requests onto an already large and growing backlog. It will likely be months before any new work can be taken up, and most pipeline requests will require weeks, if not months, to deliver.
That delay isn't just annoying. It has a price tag.
Most leaders still think of the backlog as just a list of projects to be worked through in some order. But it's not that simple. In reality, every stuck ticket is a missed opportunity, a decision on hold, or a business blind spot you don't even know you have.
Let's be clear: the problem isn't your team's talent or effort. Bluntly, it's the way they're forced to work; slow, manual, and reactive. If you want to turn the backlog from a liability into an advantage, that workflow itself has to change.
The traditional data engineering process is like running on a treadmill: you can work harder, but you're not getting ahead. Discovery drags on for weeks. Logic rewrites can take an entire quarter. Testing is tedious and manual. And just the word "documentation" is enough to generate eyerolls and belly laughs.
With big projects like legacy migrations, the queue doesn't just grow, t snowballs.
The role itself has always carried more than its fair share of burden. As we explored in The Junior Data Engineer Is Now an AI Agent, the data engineer persona is uniquely positioned to benefit from automation; not because the work is going away, but because there's always more of it than any team can handle.
All the advances in automation and agent-based tooling give you a much better way to tackle your backlog. You can shift from treating everything as a "human-only" task to a model where software agents handle the heavy lifting. This frees up your team's cycles and "think time" to be more strategic and align better with their business partners.
That's the approach behind Genesis. We've built an Agentic Data Platform designed to automate the data lifecycle so your team can focus on strategy, not grunt work.
Instead of spending weeks manually reverse-engineering legacy logic, Genesis agents convert it into clean, documented dbt models in a matter of hours. No more manually hunting for dependencies and mapping pipelines, Genesis agents automatically scan all metadata to produce a complete pipeline inventory with inferred data lineage. Where manual test writing is tedious and error-prone, Genesis agents auto-generate tests, run profile comparisons, and raise data confidence, all in a fraction of the time.
To see this in action, check out How Genesis Automates Data Pipeline Development in Hours and The Future of Data Engineering: From Months to Hours with Agentic AI.
With Genesis, teams don’t just deliver faster, they also deliver smarter. When lineage and documentation are automated, trust builds organically and compounds over time. The team isn't just clearing tickets and getting burnt out; they're spending their time on the strategic insights that were buried in the backlog to begin with.
The result? Your team stops being a ticket queue where innovation goes to die, and becomes a team that drives business forward.
If you’re tired of waiting months for answers you need today, let’s talk. There’s a better way to run data teams, and it doesn’t involve burning out your best people.
How do I know if my backlog is a risk problem, not just a capacity problem? If delayed pipeline requests are causing business decisions to stall, affecting reporting accuracy, or contributing to engineer burnout and turnover, it's a risk problem. Capacity is a symptom; the underlying issue is a workflow that doesn't scale.
Won't hiring more data engineers solve the backlog? Headcount helps in the short term, but it's the most expensive and slowest fix available. Hiring cycles are long, onboarding takes time, and the underlying manual, reactive workflow remains unchanged. The backlog tends to grow to fill whatever capacity is available.
What kinds of data pipeline tasks can be automated? The most time-consuming, repetitive tasks are the best candidates: legacy code reverse-engineering, dependency mapping, pipeline documentation, test generation, and lineage tracking. These are exactly the tasks that bog down engineers and slow delivery. For a deeper look, see The Evolution of Data Work: Introducing Agentic Data Engineering.
Will automating pipeline work put data engineers out of a job? No. It changes what they work on. Engineers move from writing boilerplate code and chasing broken pipelines to reviewing agent outputs, making architectural decisions, and partnering more directly with the business. The demand for skilled data engineers isn't going away, it's shifting toward higher-value work.
How does Genesis handle complex or legacy environments? Genesis agents are designed to work with heterogeneous environments, including legacy systems. They read existing code and documentation to infer logic, produce human-readable system-of-record documentation, and generate modernized pipelines — all without requiring the original developer to still be on the team. You can see a real-world example in GXS Uses Autonomous AI Agents to Speed Data Engineering from Months to Hours.
How do I get started with Genesis? The best first step is a demo. Genesis deploys inside your existing environment: Snowflake, Databricks, AWS, and more, so there's no rip-and-replace. Request a demo here.



.jpg)
.jpg)
.jpg)

.jpeg)
.png)
.png)
.png)
.png)
.png)
.jpeg)
.jpeg)
.jpeg)
.jpg)
%2520(1).png)
.jpg)


.jpeg)
%25201%2520(1).jpeg)

%25201%2520(1).jpeg)
.jpg)

.png)
.jpeg)
.png)
.png)
.png)
.avif)














![Agent Server [1/3]: Where Enterprise AI Agents Live, Work, and Scale](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcea_690e4d0f068d3ec27aea7ae0_123%2520(1).png)
![Agent Server [2/3]: Where Should Your Agent Server Run?](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b6f967d2ae5279adcf0_690e646b6e0366d090fbc37f_wdxczxgr-1.png)
![Agent Server [3/3]: Agent Access Control Explained: RBAC, Caller Limits, and Safer A2A](https://cdn.prod.website-files.com/67bef0c56c3781a827a0f375/69c14b56c87a1735a82bac8d_69132a45740300abc320bc7f_Cover_%2520RBAC%2520for%2520Agents%252C%2520Done%2520Right2%2520(1).png)


.png)


.jpeg)